 By
By 
Eighteen days. That is how long Claude Fable 5 and Claude Mythos 5 sat suspended after the US government's export control directive forced Anthropic to pull both models worldwide on June 12. Late on June 30, Anthropic announced that the export controls had been lifted, and that Fable 5 would return to users globally starting July 1. Mythos 5 has also been restored, though only for a select group of US organizations under Project Glasswing.
If you read our earlier piece on the ban, "When Regulators Panic Faster Than AI Labs Can Ship," you know our take at the time: a government export control on a chatbot model was an extraordinary, almost unprecedented move, and one that told us more about regulatory anxiety than about how dangerous Fable 5 actually was. Anthropic's own return announcement mostly backs that reading up. But it also reveals something users were right to be nervous about: the model coming back today is not quite the model that shipped on June 9.
What Actually Happened While Fable 5 Was Offline
According to Anthropic, the export control directive traced back to a report from Amazon researchers, who found a way to prompt Fable 5 into identifying several software vulnerabilities, and in one case, demonstrating how one of them could be exploited. Anthropic spent the following two and a half weeks working with the US government and Amazon to review the report.
The company's conclusion is that this was not a uniquely dangerous capability. Anthropic says it tested a range of other models, including Opus 4.8, GPT-5.5, and Kimi K2.7, and found they could all identify the same vulnerabilities Fable 5 did. Every model tested, down to Claude Haiku 4.5, could reproduce the single exploit demonstration as well. In Anthropic's framing, the government acted on what turned out to be a fairly ordinary defensive cybersecurity capability that happened to sit just inside a grey zone in Fable 5's safety net, not a genuine Mythos-level breach.
That framing is convenient for Anthropic, but it is also consistent with what independent researchers have said publicly, and it lines up with our original argument that this looked more like a regulator moving fast on incomplete information than a confirmed catastrophic capability.
The Part Users Should Actually Care About: A Stricter Classifier
Here is where the story gets more interesting for anyone who actually plans to use Fable 5 again. To satisfy the government and get the export controls lifted, Anthropic trained a new safety classifier specifically targeting the technique Amazon's researchers used. Anthropic says this closes off the reported bypass in more than 99 percent of cases.
The catch, which Anthropic states plainly in its own announcement, is that the new classifier will flag more benign requests during ordinary coding and debugging work. When a request gets flagged, it does not get refused outright. It gets silently rerouted to Claude Opus 4.8, and Fable 5 returns that response instead.
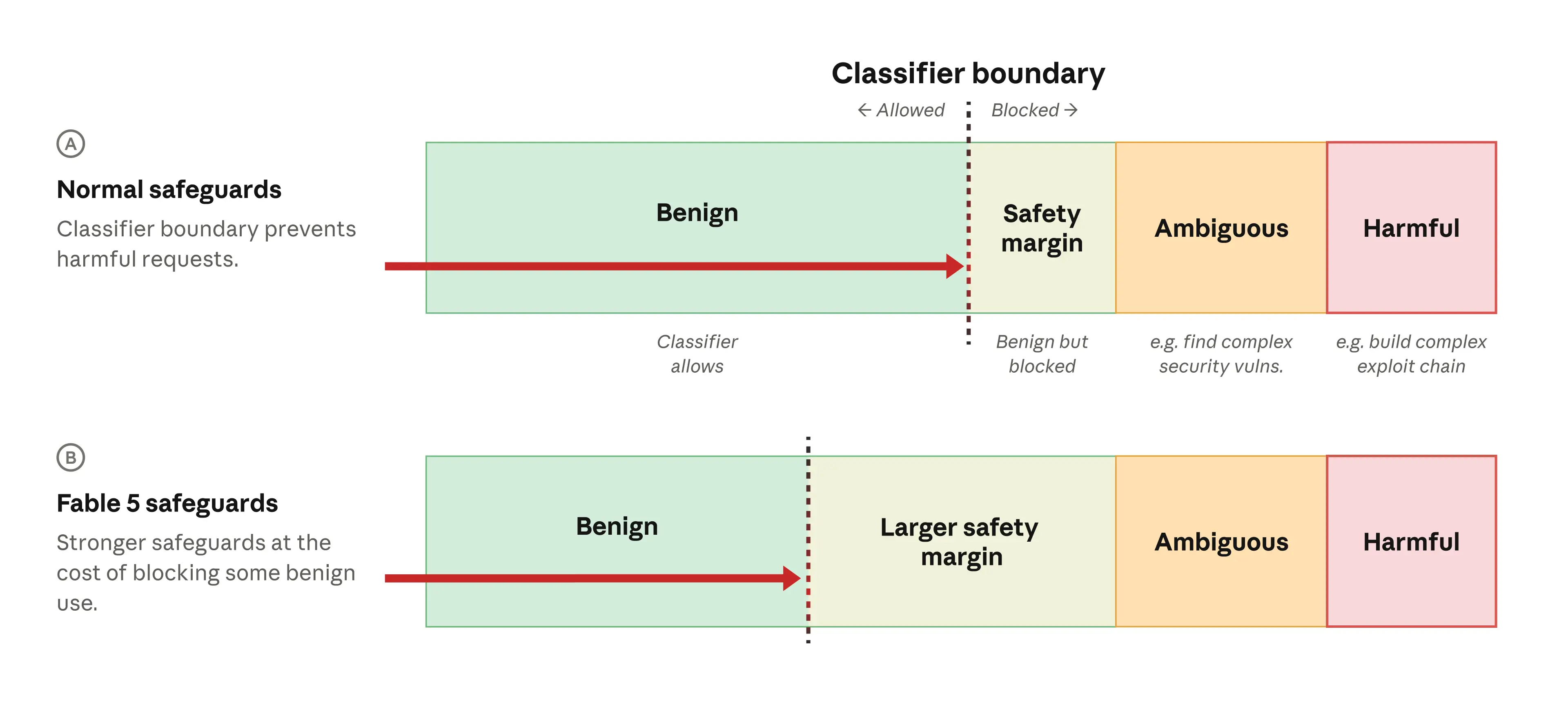
This is not a new mechanism. Fable 5 launched with this kind of routing back in June, covering cybersecurity, biology, chemistry, and model distillation queries. What has changed is the sensitivity. The safety margin, in Anthropic's own words, has been widened again, which means the model you get back today has a narrower band of tasks it will actually handle at full Fable 5 capability compared to the one that launched three weeks ago.
For everyday users, this mostly shows up as friction: a coding or debugging session that would have run entirely on Fable 5 in early June might now bounce partway through to Opus 4.8, a model that already scored meaningfully lower on the benchmarks that made Fable 5 exciting in the first place. Anthropic frames this as a temporary cost of getting the model back online, and says it will keep refining the classifier to cut down false positives. Whether that refinement happens quickly or slowly will decide how much of the original hype around Fable 5 survives contact with its new, more cautious safety layer.
Why Users Are Skeptical, and Why That Skepticism Is Reasonable
The reaction we have seen since the announcement broke has been closer to wary than relieved. Part of that is fatigue. Fable 5 launched on June 9 already carrying a reputation for aggressive safety refusals, on top of pricing set at double Opus 4.8's rate. It got pulled entirely within three days. Now it is back, but tighter, and Anthropic has been upfront that this will cost users some day-to-day usability in exchange for satisfying the government.
There is also a structural reason to be skeptical that goes beyond vibes. Anthropic's own document notes that the improved classifier still cannot fully eliminate false negatives, and openly says the model's safeguards are not designed to allow every low-risk cybersecurity task through, only the ones judged unlikely to be harmful. That is a wide margin for interpretation, and it means individual users will not always be able to predict in advance whether a legitimate debugging question gets answered by Fable 5 or quietly handed off to Opus 4.8.
Our view is that this skepticism is fair without being alarmist. Nothing in Anthropic's announcement suggests Fable 5 has become less capable at the model level. What has changed is how often that capability is actually reachable by a normal user typing a normal prompt. That distinction matters a lot if you are choosing whether to route production workloads through Fable 5, and a lot less if you are just curious what the fuss was about.
A New Industry Standard for Jailbreaks, and Deeper Government Ties
The more consequential part of Anthropic's announcement, at least for the industry as a whole, is not about Fable 5 specifically. Anthropic says it is now working with Amazon, Microsoft, Google, and other Project Glasswing partners to build a shared framework for scoring the severity of AI jailbreaks, based on four criteria: how much capability a jailbreak actually unlocks, how broadly that capability applies, how easy the jailbreak is to turn into a real attack, and how easy the technique is to discover in the first place.
This is Anthropic trying to solve the exact problem we flagged in our original article: regulators currently have no consistent way to judge whether a reported jailbreak is a minor annoyance or a genuine emergency, so they default to the bluntest possible response. A shared industry standard, if other major labs actually adopt it, would give governments a calibrated basis for action instead of a binary choice between doing nothing and shutting a model down worldwide. It is a sensible idea on paper. Whether it holds up the next time a lab gets a similar report will say a lot about whether this was a genuine fix or a public relations exercise dressed up as policy.
Anthropic is also formalizing deeper ties with the US government, including pre-release access for government evaluators on future frontier models and faster information sharing when new jailbreaks or misuse patterns turn up. Read generously, this is Anthropic trying to prevent a repeat of the three-day shutdown. Read more cynically, it is also Anthropic embedding itself further into the exact kind of government relationship that reinforces its narrative of being the lab responsible enough to be trusted with the most powerful models, a narrative we discussed at length in our earlier piece.
Meanwhile, Sonnet 5 Just Quietly Became the More Interesting Release
Almost lost in the Fable 5 news is that Anthropic also launched Claude Sonnet 5 on June 30, and for most people, it is probably the more useful update. Sonnet 5 is now the default model on Free and Pro plans, and Anthropic is pitching it as its most agentic Sonnet model yet, capable of planning, using browsers and terminals, and running multi-step tasks with less hand-holding than before.
The numbers back that positioning up reasonably well. On agentic coding benchmarks, Sonnet 5 scores close to Opus 4.8 while costing roughly 40 percent less at standard pricing, and less than half as much during its introductory pricing window, which runs through August 31 at 2 dollars per million input tokens and 10 dollars per million output tokens. On knowledge work tasks, some reports have Sonnet 5 edging out Opus 4.8 entirely.
Just as importantly, Sonnet 5 shipped with Anthropic's standard cybersecurity safeguards rather than the tightened protections that triggered the Fable 5 saga. Anthropic says the model never produced a fully working software exploit during testing, which is presumably why it did not need the same kind of defense-in-depth treatment. For most developers and everyday users in Kenya and elsewhere who do not need Fable-level capability at Fable-level prices, Sonnet 5 is likely to be the model that actually shapes daily workflows over the next few months, while Fable 5 remains the headline-grabbing but comparatively niche option.
What We're Watching Next
A few things will tell us whether this restoration actually resolves the underlying problem or just papers over it. First, whether Anthropic's false-positive rate on coding and debugging tasks comes down meaningfully in the weeks ahead, or whether users are stuck with a Fable 5 that behaves like Opus 4.8 more often than advertised. Second, whether the proposed jailbreak severity framework gets adopted by other labs in a form users can actually see applied, rather than staying a policy document. Third, whether Mythos 5's slow, partner-by-partner rollout under Project Glasswing continues to expand, or whether it stays limited to a small circle of trusted US organizations indefinitely.
None of this changes our core read from three weeks ago. A government being willing to shut down a commercial AI product worldwide within three days of launch, based on a report it has not fully disclosed, is a bigger story than whether that particular product turns out to be dangerous. What this week adds is a second data point: even after the ban is lifted, the settlement extracted from Anthropic makes the model itself more conservative, not less. Regulatory pressure did not just pause Fable 5. It appears to have permanently narrowed it.
Comments