 By
By 
In the rapidly evolving landscape of 2026, the boundary between human-generated and AI-generated content has become almost entirely imperceptible. As generative models like Google’s Gemini produce images and videos with staggering realism, the tech industry has scrambled to find a "digital fingerprint" that can prove an image's origin without marring its visual beauty. This quest led to the birth of Google DeepMind’s SynthID, a sophisticated, invisible watermarking system designed to label AI creations at the pixel level.
However, the safety and permanence of these invisible signatures were recently thrown into question. A project titled reverse-SynthID has appeared on GitHub, demonstrating that the "unbreakable" watermark can be identified, mapped, and surgically removed using nothing more than standard signal processing techniques. This development marks a pivotal moment in the history of AI safety, as it forces us to confront a difficult reality: in the digital realm, what can be hidden can almost always be found.
What is SynthID? The Quest for Invisible Accountability

To understand why the reverse engineering of this system is so significant, we must first understand what SynthID actually is. Unlike traditional watermarks that place a visible logo in the corner of an image, SynthID is embedded into the very fabric of the file. It does not exist as a separate layer or a piece of metadata like a file name or a GPS coordinate. Instead, it is woven into the pixels during the generation process itself.
The primary goal of SynthID is to provide a "resilient" identifier. Google designed the system to survive common edits that usually strip away metadata, such as cropping, resizing, or aggressive JPEG compression. When a user creates an image with Gemini, the model applies a subtle, mathematically precise pattern across the image. While this pattern is invisible to the human eye, Google’s specialized detection algorithms can spot it with high confidence, allowing the company to label content as "AI-generated" on platforms like YouTube and Google Search.
The Science of Invisibility: How it Works Technically
The magic of SynthID lies in the "frequency domain" of an image. If you think of an image as a collection of colors and shapes, that is the spatial domain. However, an image can also be thought of as a collection of waves and frequencies. High frequencies represent sharp edges and fine details, while low frequencies represent smooth gradients and broad colors.
SynthID works by making microscopic adjustments to these frequency components. Specifically, it uses a technique involving "wavelet transforms" and "spectral analysis." The watermark is distributed across the entire visual spectrum of the image. By spreading the information so thinly and broadly, the system ensures that no single edit can destroy the watermark without also destroying the quality of the image itself.
Google’s neural networks are trained to "read" these specific frequency shifts. Even if you take a screenshot of a Gemini image and post it to a different social network, the frequency patterns remain embedded in the pixels. This "pixel-level" approach was hailed as a breakthrough because it bypassed the fragility of previous metadata-based systems.
The Breach: How Reverse-SynthID Cracked the Code
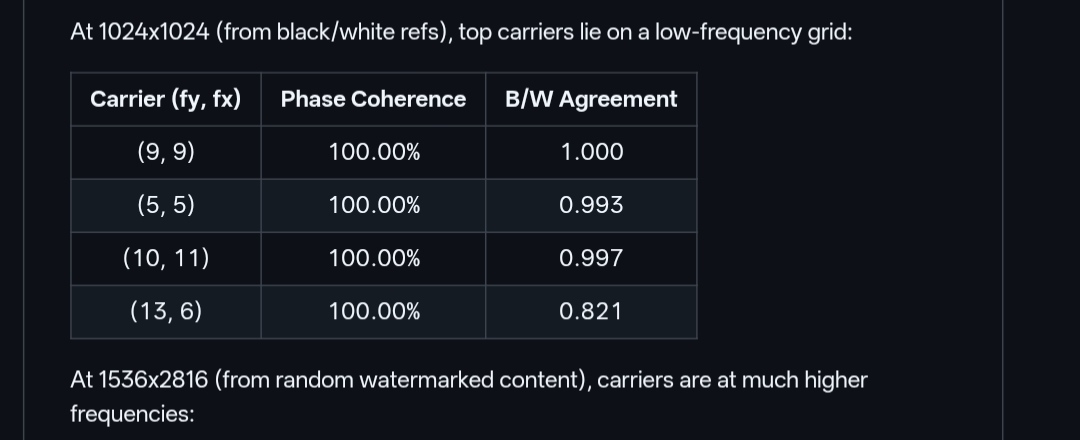
The reverse-SynthID project, made open source on GitHub by researcher Alosh Denny, took a different approach. Rather than trying to "guess" how the watermark was made, the project used signal processing to "see" the invisible. By analyzing thousands of images generated by Gemini, specifically including pure black and pure white "reference" images, the researcher was able to identify the exact "carrier frequencies" where the watermark lives.
The breakthrough came through the discovery of the "SpectralCodebook." It turns out that SynthID uses specific frequency coordinates that change based on the resolution of the image. A 1024x1024 image has its watermark hidden in a different "bin" than a 1536x2816 image. The GitHub project meticulously mapped these coordinates across various resolutions, creating a master key that can identify the watermark with approximately 90% accuracy.
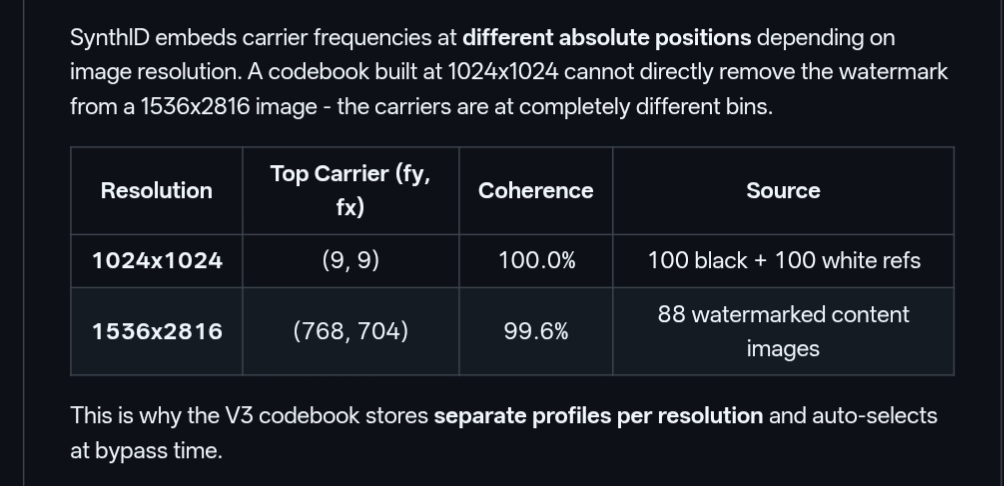

Perhaps the most impressive (and concerning) part of the project is the "V3 Bypass" method. Once the carrier frequencies are identified, the tool can perform "spectral subtraction." It essentially identifies the "noise" added by the watermark and subtracts it from the image's frequency map. This results in a "bleached" image where the watermark is over 90% gone, but the image quality remains nearly perfect. This process is far more sophisticated than simply blurring an image; it is a surgical extraction of the safety feature itself.
The Practical Implications: A Blow to Automated Detection
The practical fallout of this project is immediate and far-reaching. For the past year, the industry has relied on the idea that invisible watermarks would be the primary defense against the spread of misinformation. Social media platforms were expected to use these detectors to automatically label political deepfakes or non-consensual AI imagery.
If a simple open-source tool can remove these watermarks, that defense layer effectively evaporates. A bad actor can generate a deceptive image using Gemini, run it through the reverse-SynthID bypass, and then upload it to the web. Because the watermark is gone, the automated safety systems of other platforms will see the file as a "clean" original. This places the burden of verification back on human fact-checkers, who are already overwhelmed by the sheer volume of synthetic media.
Furthermore, this creates a "security theater" problem. If platforms tell users that they "automatically detect AI content," but those detectors can be bypassed by anyone with a GitHub account, it creates a false sense of security. Users might assume that an image is real simply because it lacks an "AI-generated" label, when in reality, the label was just professionally removed.
Ethical Dilemmas: The Ethics of Disclosure
The release of this project has sparked a fierce debate within the AI research community. On one hand, there is the "Open Source" philosophy. Proponents argue that by exposing the weaknesses in Google’s system, the researcher is performing a vital public service. They argue that if a safety system is this easy to break, it was never actually safe to begin with. By making the flaw public, they force Google and other companies to build more robust, truly "unbreakable" systems.
On the other hand, many ethicists argue that open-sourcing a "bypass" tool is inherently irresponsible. Unlike a traditional software bug, which can be patched with a line of code, the "bug" in SynthID is a fundamental mathematical trade-off. There may not be a way to make an invisible watermark that is also immune to spectral analysis. In this view, the researcher hasn't helped "fix" anything; they have simply handed a set of lock-picks to every digital criminal on the internet.
This situation mirrors the early days of "jailbreaking" iPhones or bypassing DVD encryption. While the researchers often have academic or "white-hat" intentions, the tools they create are inevitably used for less noble purposes. In the context of 2026, where AI-generated misinformation can influence elections and destroy reputations, the stakes of "academic exploration" are higher than they have ever been.
The Future of Content Provenance: Beyond Watermarks
The success of the reverse-SynthID project suggests that we are moving away from a world of "detection" and toward a world of "provenance." Detection is a reactive game: you look at a file and try to guess if it is AI. Provenance is a proactive game: you track the file from the moment it is created.
This is where standards like C2PA (Coalition for Content Provenance and Authenticity) come into play. Instead of hiding a secret pattern in the pixels, C2PA uses "cryptographic signing." When a camera takes a photo, or an AI model generates an image, it attaches a digital signature that is verified by a chain of trust. If any part of the image is changed, the signature breaks.
The advantage of C2PA is that it doesn't rely on "invisibility" for its strength. Its strength comes from mathematics and encryption. However, the disadvantage is that it is much easier to "strip" C2PA metadata than it is to remove a pixel-level watermark. This has led to the current "hybrid" approach, where companies like Google try to use both. But as the reverse-SynthID project proves, even the most clever pixel-level patterns are ultimately just data, and data can be manipulated.
Personal Insights: The Endless Cat-and-Mouse Game
As someone who watches these technical developments closely, I find the reverse-SynthID situation to be a classic example of the "Arms Race" in technology. For every shield we build, someone will build a sharper sword. It is tempting to look at Google’s failure here and call it a defeat for AI safety, but I think that is the wrong takeaway.
The real lesson is that we cannot rely on a single technical "silver bullet" to solve the problem of AI transparency. Watermarking is a useful tool, but it is not a complete solution. We must treat AI safety as a multi-layered defense. This includes better education for the public, more robust cryptographic standards like C2PA, and legislation that holds individuals accountable for the malicious use of AI tools, regardless of whether a watermark is present or not.
The creator of reverse-SynthID has effectively held up a mirror to the industry and shown us that our "invisible" defenses are more fragile than we cared to admit. It is a uncomfortable realization, but it is a necessary one if we want to build a more honest digital future.
Conclusion: A Turning Point for Digital Trust
The release of the reverse-SynthID project on GitHub marks the end of the "innocent" era of AI watermarking. We can no longer assume that an invisible mark in a pixel is a permanent record of truth. As the "bypass" tools become more accessible, the value of traditional watermarking will likely decrease, forcing the industry to innovate yet again.
We are entering a period where "digital trust" will be harder to earn and easier to lose. Whether through more advanced neural watermarking that adapts to spectral analysis or through a global shift toward cryptographic signing, the way we verify reality is about to undergo a radical transformation. The GitHub project is not just a collection of code; it is a signal that the "cat-and-mouse" game of AI detection has officially entered its most dangerous and sophisticated phase yet.
Comments